
Sitemap
A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Pages
Posts
Future Blog Post
Published:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Blog Post number 4
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 3
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 2
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 1
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
experience
MedPrime Technologies - Data Science Intern (December 2019)
MedPrime Technologies is a pioneering medical device company dedicated to creating customer-centric solutions for global healthcare needs. During my second year of undergrad, I collaborated closely with the CTO through an internship to design a Python-based backend software that assists doctors in predicting the suitability of sperm samples for Human IVF.
Huawei India RnD - Data Science Intern (July 2020)
I developed a machine learning model for speech language detection, leveraging mel-spectrogram images and multi-label classification techniques from computer vision. Using CNN architectures like InceptionV3, DenseNet201, and VGG16, I trained models on datasets such as LibriSpeech and CommonVoice, achieving 97% accuracy in detecting European languages. For Automatic Speech Recognition (ASR), I trained the Jasper Network with CTC loss for English and applied transfer learning to Spanish, achieving a competitive 19.78% WER for Spanish ASR. To improve transcription accuracy, I integrated spelling correction models like DeepPavlov and Enchant, reducing English ASR errors by 7%. Additionally, I explored ASR for music lyric transcription by isolating vocals using Spleeter but identified challenges due to background noise and artistic pronunciation variations.
ABInBev India - Automation Intern (May 2021)
I analyzed €8.4M in correction amounts for the Belgium Business Division, identifying invoicing errors and developing seven KPIs to enhance billing accuracy while cataloging SAP tables for data aggregation. For the Mexico Business Division, I debugged 10+ data metrics and developed knowledge models for Overdues and Accounts Receivable, enabling effective rework tracking. I also designed three global sales order trackers and documented analysis dashboards for business-friendly use.
Accenture Labs India - Research Intern (Oct 2021)
I developed a framework to enhance the diversity of a small in-lab gesture video dataset by researching state-of-the-art synthetic video generation methods and implementing augmentations using OpenCV and Pillow. The automated framework increased video samples by 100 times through systematic application of blurring, random cropping, and affine transformations. Using the synthetic dataset, I trained and evaluated deep learning models like MocoGAN and TecoGAN, identifying GAN-based methods as optimal for limited gold-standard datasets. This approach led to a 10% relative improvement in classification performance over competitive baselines. Additionally, I identified the limitations of mechanical augmentations and recommended diffusion models for more sophisticated data augmentation.
projects

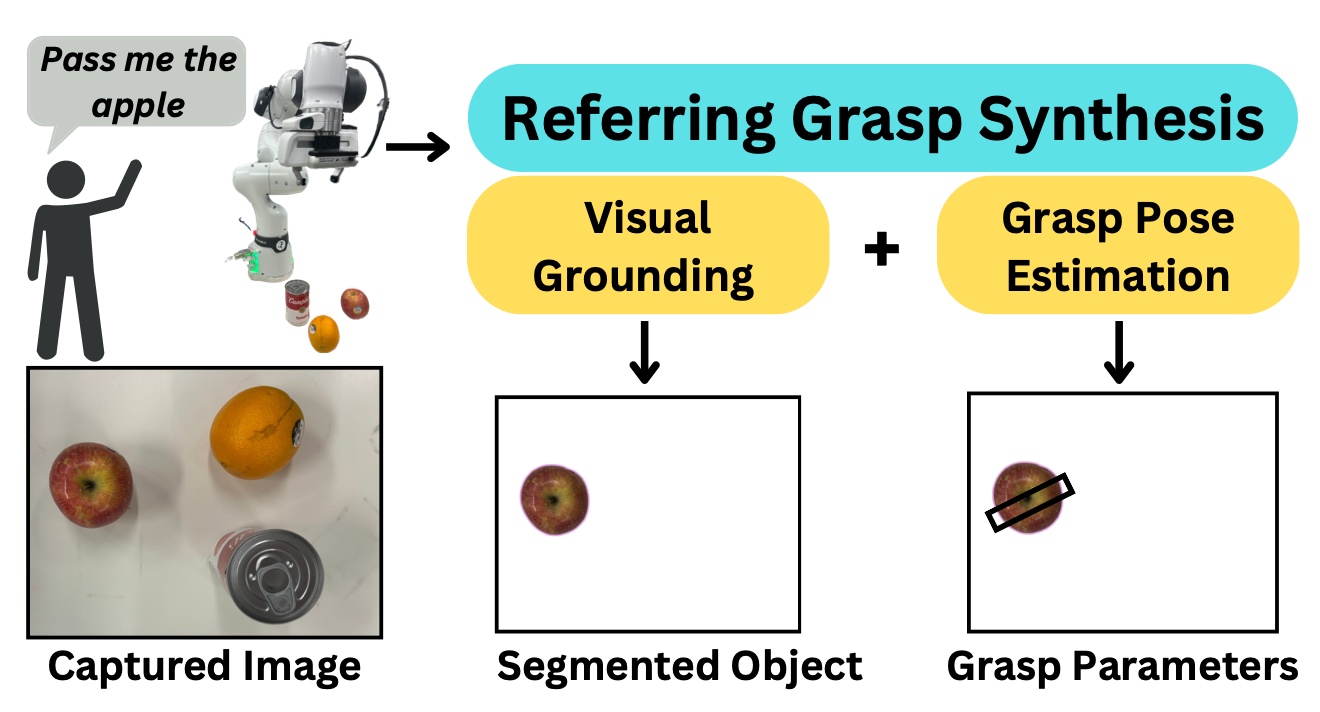
publications
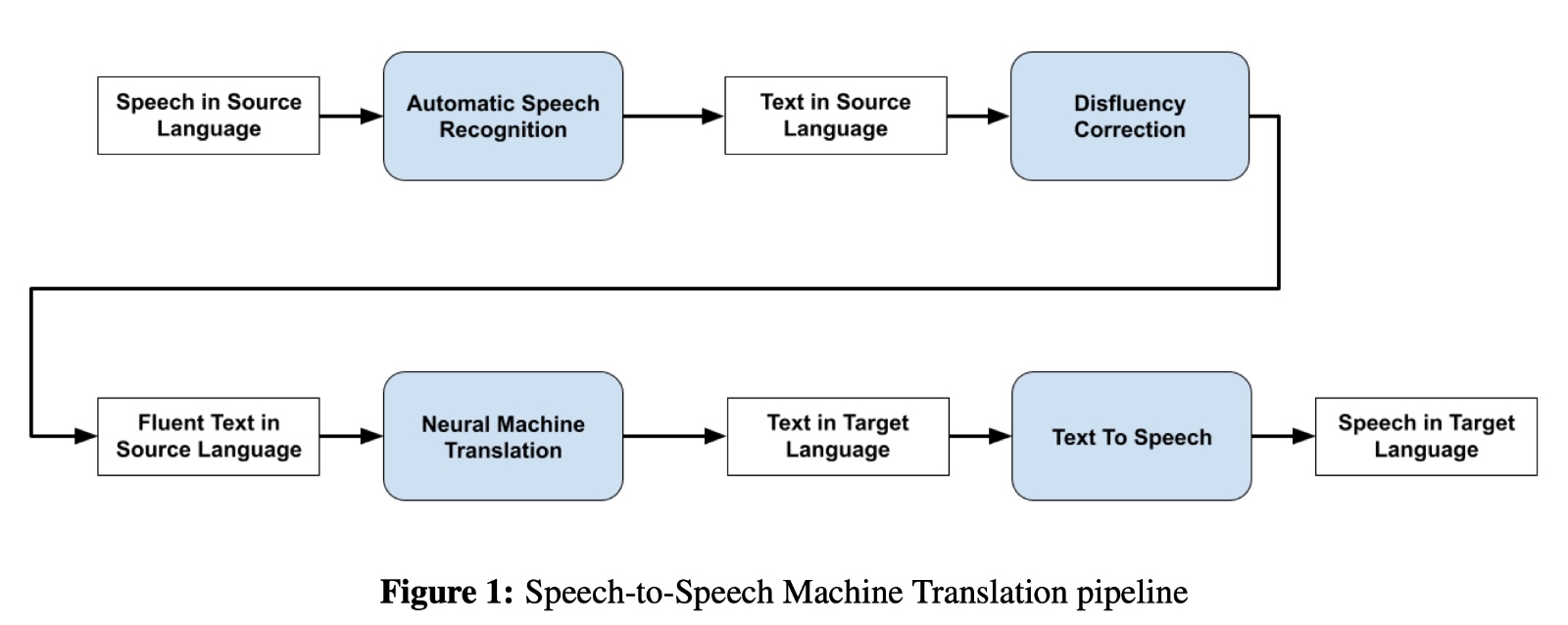
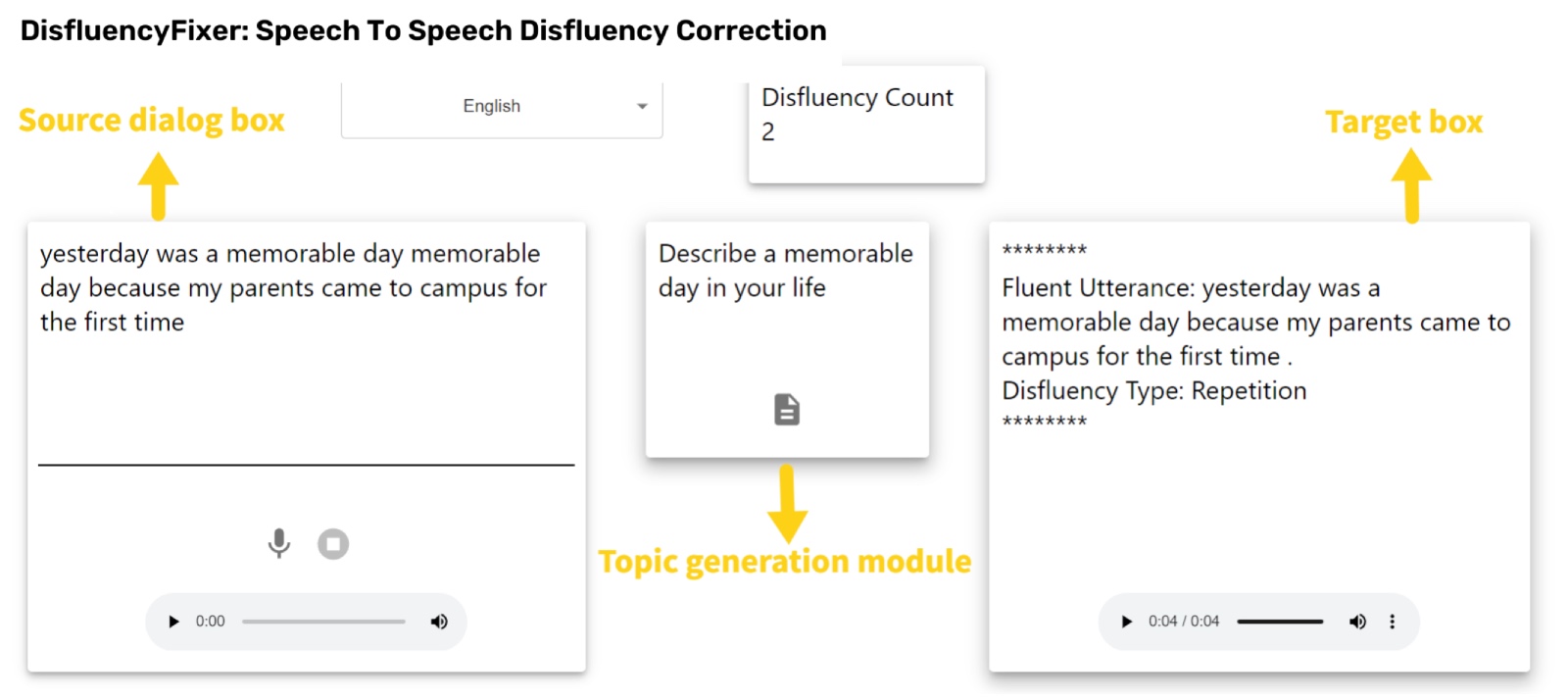
DisfluencyFixer- A tool to enhance Language Learning through Speech To Speech Disfluency Correction
Published in Interspeech (Show and Tell Demonstrations), 2023
In this work, we create a webservice demonstrating capabilities of speech to speech disfluency correction. Given a disfluent speech utterance in English or Hindi, the model first transcribes the speech using a powerful Speech To Text system. The transcribed text is cleaned using our SOTA disfluency correction models followed by speech synthesis.
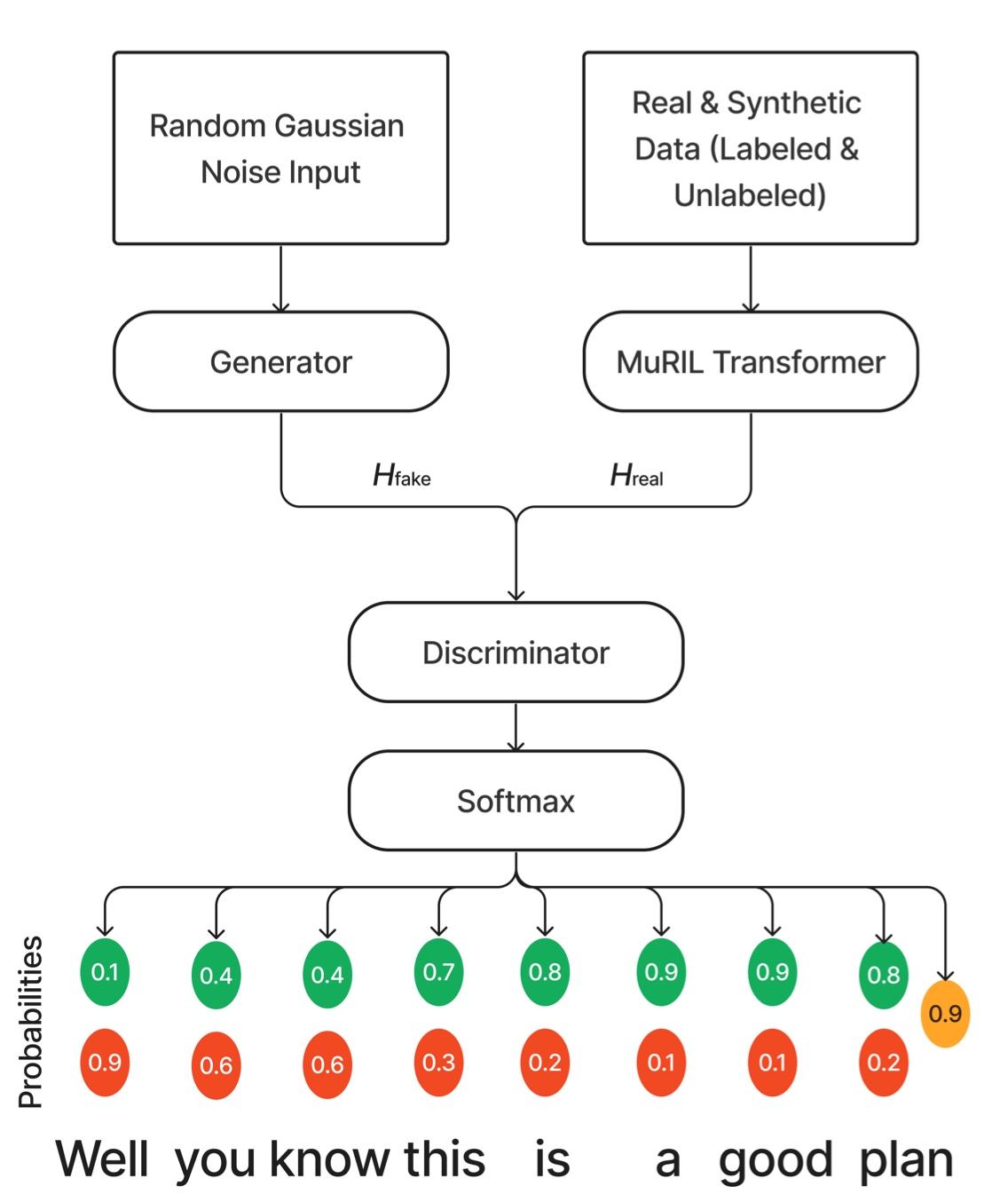
Adversarial Training for Low-Resource Disfluency Correction
Published in Association for Computational Linguistics (ACL) (Findings), 2023
This paper introduces Seq-GAN-BERT, a novel few shot machine learning approach leveraging a small set of labelled examples and large set of unlabelled examples for low resource disfluency correction.
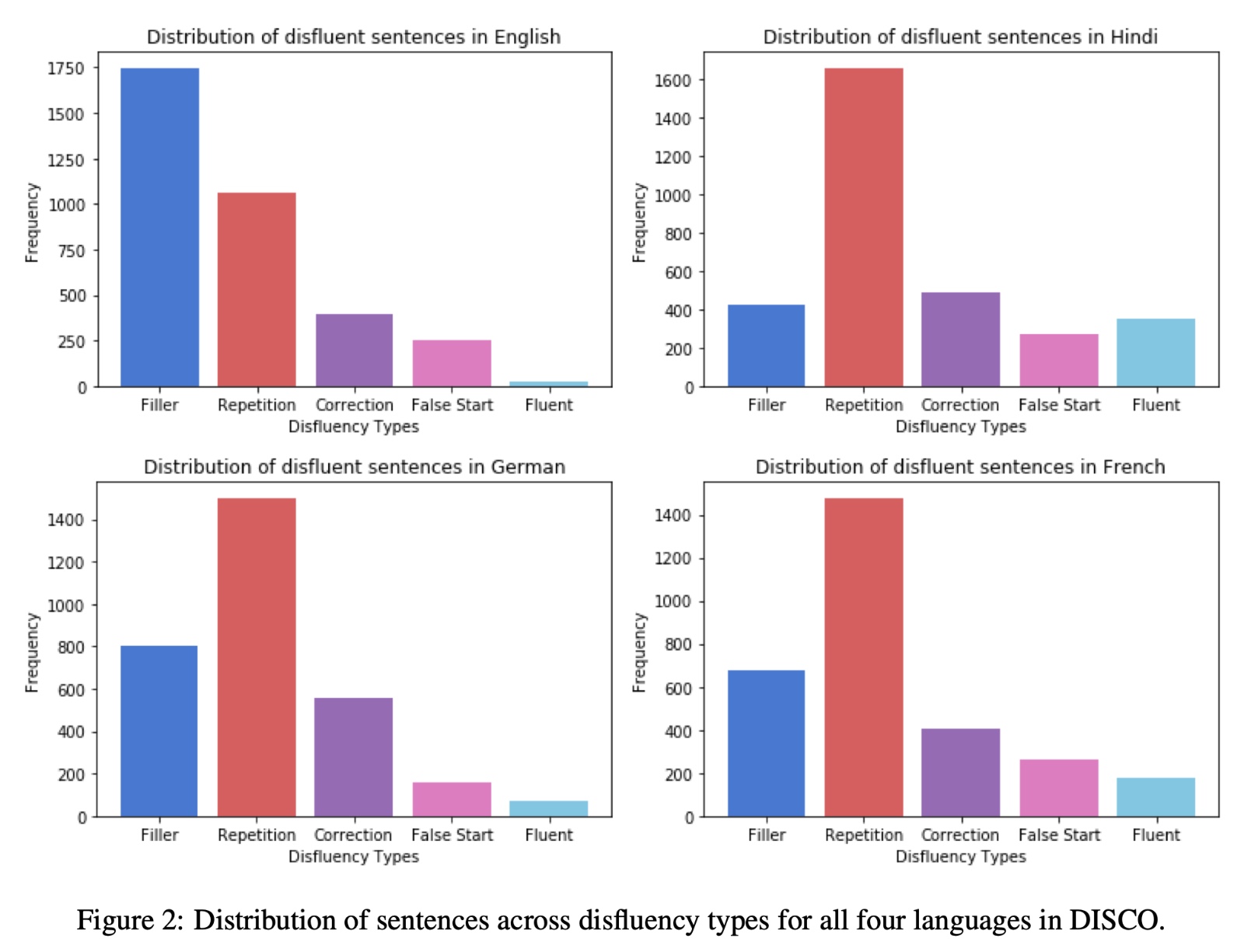
DISCO: A Large Scale Human Annotated Corpus for Disfluency Correction in Indo-European Languages
Published in Empirical Methods in Natural Language Processing (EMNLP) (Findings), 2023
Through this project, we created a novel dataset for Disfluency Correction in English and 3 under-represented languages - Hindi, German and French. We benchmarked various transformer architectures for sequence labelling styled disfluency correction, and demonstrate key features of the proposed dataset that previous works was lacking.
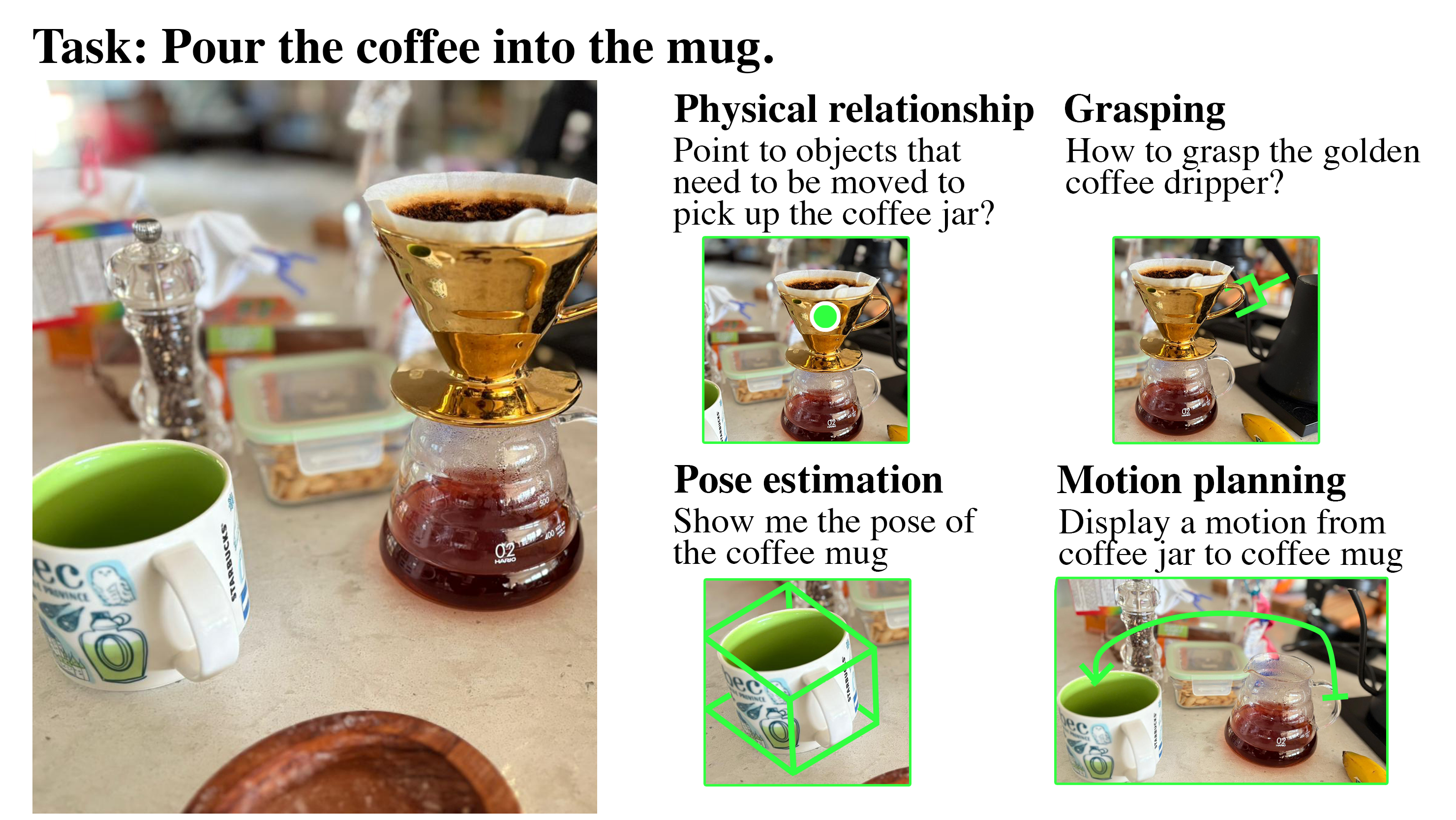
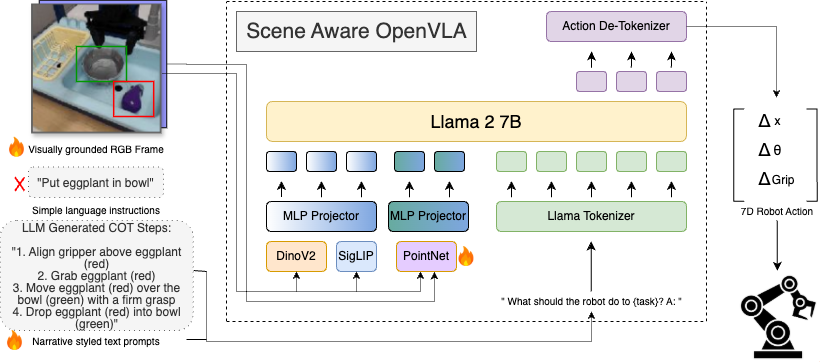
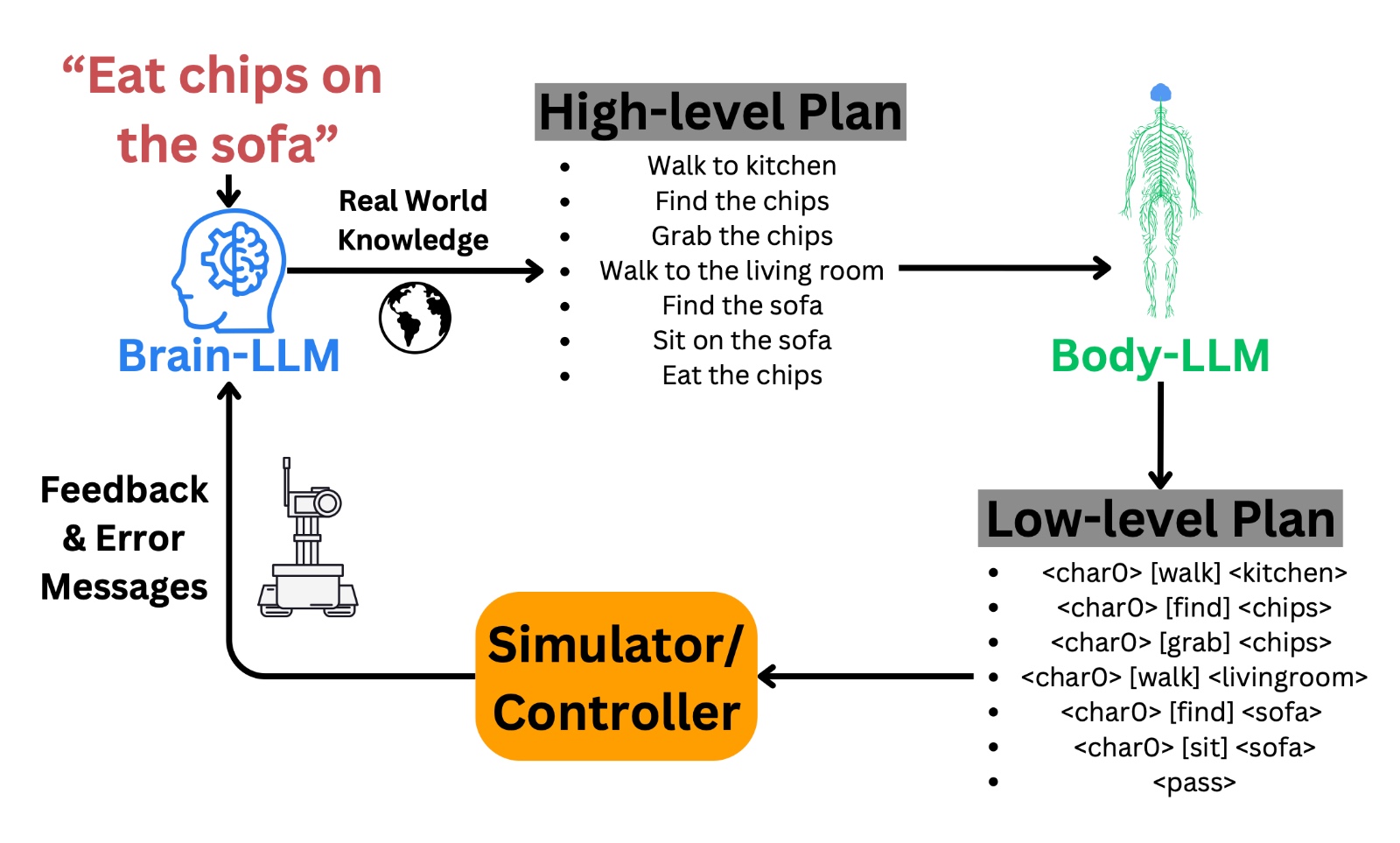
Grounding LLMs For Robot Task Planning Using Closed-loop State Feedback
Published in ArXiv Preprint, 2024
This paper discusses a novel approach to robotic task planning, using a Two-LLM system for breaking down a complex task into executable plans followed by grounding to the robotic environment. We leverage environmental state information and error messages during execution to guide the LLM planner for task resolution. Our paper achieves improved results in the popular VirtualHome robotic simulation environment